웹 크롤링
웹 크롤링 기초 과정입니다.
제가 제일 처음 배웠던 웹 크롤링으로써
처음 체험하는데 가장 좋은 예시가 될 수 있을 것 같아
글을 적게 되었습니다.
파란색으로 남긴 글이
코드이기에
본 게시글을 보시면서
파란글을 R studio에 붙여넣기 하시면
이해가 더 쉽게 될 것입니다.
게시글 시작하겠습니다 !
library(rvest) #크롤링을 위한 라이브러리
크롤링만 진행할 것이기에
rvest만 있어도 충분히 크롤링이 가능합니다.
필요한 라이브러리 기입입니다.
전처리 내용을 워드클라우드까지 제작해 보는 것을 목표로 진행하였습니다.
지금 블로그 글에서는 크롤링까지 진행해보겠습니다.
처음에는 다음 뉴스 기사 크롤링입니다.
많은 분들이 시도하였고 좋은 예시라고 생각하기에
제일 먼저 이 방법을 선택하여 진행하였습니다.
**** 언론사 별로 뉴스 기사 내용이 형식 및 구조가 많이 달랐었습니다.
그렇기에 언론사 하나를 특정하여 진행하였습니다 ****
순서는
1. 목록별로 나타나있는 뉴스기사 페이지를 몇 페이지까지 추출할건지 정하고 추출한 만큼의 URL을 추출합니다.
2. 페이지 URL을 추출했다면, 뉴스 기사로 접속하기 위한 URL을 추출합니다.
3. 마지막으로 뉴스 기사 URL로 접속하여 그 안의 뉴스 내용을 추출합니다.
1. 페이지 URL 추출입니다.

먼저 다음 뉴스 탭에 들어가서 빅데이터를 검색해줍니다.
여기서 언론사 별로 나타내야하기에 중간의 <언론사>를 클릭하여 설정해줘야 합니다.
IT뉴스로 유명한 '전자 신문'에서 추출할 예정이기에 전자신문으로 알맞게 설정하여줍니다.

언론사를 전자신문으로 활용하였습니다.
전자 신문은 데이터 관련 뉴스로 유명한 언론사 이기도 하며
크롤링하기 용이한 언론사라 선택하게 되었습니다.
이유는 밑에서 말씀 드리겠습니다.
현재 페이지의 URL을 이용하여 10페이지까지의 URL을 추출하도록 하겠습니다.
현재 페이지의 URL은
빅데이터 – Daum 검색
Daum 검색에서 빅데이터에 대한 최신정보를 찾아보세요.
search.daum.net
입니다.
1페이지의 URL이기에 마지막에 1이 적혀있는 모습을 보이고 있습니다.
예상하셨듯이 저 부분에 2를 적으면 2페이지, 3을 적으면 3페이지가 나올기에
간단한 반복문을 사용하여 10페이지까지 추출할 수 있습니다.
시작하는 페이지를 basic_url 변수로 시작하겠습니다.
basic_url <- 'https://search.daum.net/search?w=news&DA=STC&enc=utf8&cluster=y&cluster_page=1&q=%EB%B9%85%EB%8D%B0%EC%9D%B4%ED%84%
B0&cpname=%EC%A0%84%EC%9E%90%EC%8B%A0%EB%AC%B8&cp=16sIQ8rx97vi9RHx8w&p='
-> 반복문을 사용하여 1부터 10을 직접 URL에 넣어줄 예정이기에 마지막에 있던 숫자는 지우고 변수를 지정하였습니다.
urls <- NULL
-> 첫 페이지부터 추출하고자 하는 페이지까지 크롤링한 내용을 담아줄 변수 설정
cnt <- 0
for(i in 1:10){
cnt = cnt+1
urls[cnt] <- paste0(basic_url, i,"&DA=PGD") #basic_url과 i를 이어붙임
}
->기본 주소에 paste를 사용하여 반복할 페이지 설정
cnt를 이용하여 인덱싱,
즉 url[0]을 지정하여 urls변수에 10페이지까지의 url을 저장하여줍니다.

urls를 출력하여 10개의 페이지를 출력 완료한 모습입니다.
2. 뉴스 기사 페이지 url 추출
이제는 뉴스 기사가 기제되어 있는 url을 가져 올 차례입니다.

10개의 뉴스 기사를 묶고 있는 저 부분을 추출한 다음 세부적인 내용을 다시금 추출하는 과정을 거칩니다.
저 부분을 추출하기 위해선 현재 페이지의 html코드를 가져 올 필요가 있습니다. 그렇기에
read_html(urls)를 사용합니다.
그리고 위의 사진의 파란 부분의 xpath를 추출하는 과정을 거칩니다.
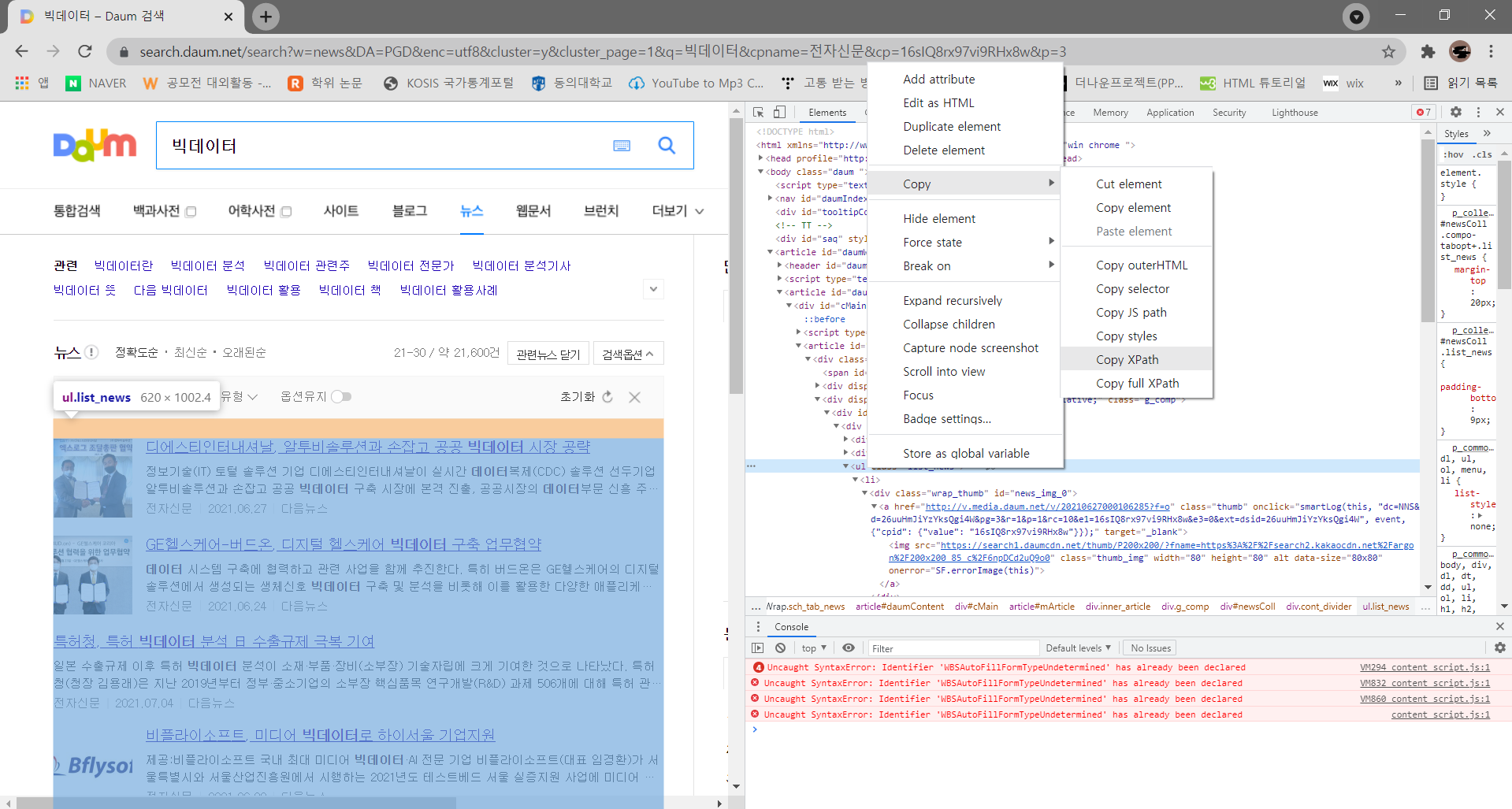
추출한 xpath를 더불어

자세히 보시면 a 태그로 뉴스 기사가 있는 url이 묶여 있는 것을 확인할 수 있습니다.
a태그만 그대로 추출하면 뒤에 있는 내용도 다 같이 나오기에
href를 따로 또 적어줌으로써 우리가 원하는 url 부분만 추출하게 만들었습니다.
links <- NULL
for(url in urls){
html <- read_html(url) #해당 페이지의 html을 모두 추출.
html2 <- html_nodes(html,
xpath = '//*[@id="newsColl"]/div[1]/ul') #소스코드를 추출함
html3 <- html_nodes(html2, 'a') #html2에서 a태그 추출하여 html3에 저장
links <- c(links, html_attr(html3, 'href')) #html3에서 href 속성 추출하여 links에 추가
links <- unique(links) #중복된 링크 제거
}
3. 뉴스 기사 내용 추출
본격 적인 뉴스 기사 내용 추출입니다.
현재 시간 21년 08월 19일 20시 전자 신문의 제일 최근 뉴스 기사 내용입니다.

앞의 내용과 비슷한 내용의 반복입니다.
뉴스 기사 내용이 있는 부분을 살펴보면
모두 P 태그에 묶여 있는 것을 확인하실 수 있습니다.
전자 신문이란 언론사를 선택한 이유가 여기 있습니다.
P태그 하나에 모든 내용이 묶여 있기에
크롤링을 체험해보기에 최적화된 언론사라고 할 수 있습니다.
그렇기에
read_html() 을 사용하여 links에 저장된 url을 하나씩 불러오고,
html_nodes() 를 사용하여 P태그 안의 내용만 추출한다면,
목표로 했던 뉴스 기사를 추출해 낼 수 있을 것입니다.
txts <- NULL
for(link in links){
html <- read_html(link) # links에 저장된 url을 하나씩 불러온다.
txts <- c(txts,html #txts와 html은 저장될것이다.
%>% html_nodes('p') #url의 개발자 소스에서 p태그만 가져와라.
%>% html_text()) #텍스트만 추출하라
}
length(txts)
txts[1]

txts[1]을 사용하여 제일 최근 뉴스 기사를 불러보았습니다.
txts만 기입하여 출력한다면 2805개의 뉴스 기사가 갑자기 출력되면
뭐가 뭔지도 모른채 제일 오래된 기사만 보게 된답니다.
간단하면서도 간단하지 않은 크롤링은
기본만 다져놓고 꼼꼼하게 전처리를 한다면
지금보다 고급 기술로 더 많은 크롤링을 할 수 있을 것 같습니다.
오늘의 글은 여기까지고
틈틈히 제가 했던 목록들을 올려나가겠습니다.
오늘도 감사합니다.
출처: 전자신문